
Vaex is an open-source DataFrame library for Python with an API that closely resembles that of Pandas. I have been using Vaex for several years in both academic and industry environments, and it is my go-to library for several of the data science projects I am working on. In this article I would like to share some of my favourite Vaex features. Some may be obvious by now, but some may surprise you.
The following code examples are run on a MacBook Pro (15", 2018, 2.6GHz Intel Core i7, 32GB RAM). This article can also be read as a Jupyter Notebook.
1. Easy to work with very large datasets
Nowadays, it becomes increasingly more common to encounter datasets that are larger than the available RAM on a typical laptop or a desktop workstation. Vaex solves this problem rather elegantly by the use of memory mapping and lazy evaluations. As long as your data is stored in a memory mappable file format such as Apache Arrow or HDF5, Vaex will open it instantly, no matter how large it is, or how much RAM your machine has. In fact, Vaex is only limited by the amount of free disk space you have. If your data is not in a memory-mappable file format (e.g. CSV, JSON), you can easily convert it by using the rich Pandas I/O in combination with Vaex. See this guide on how to do so.
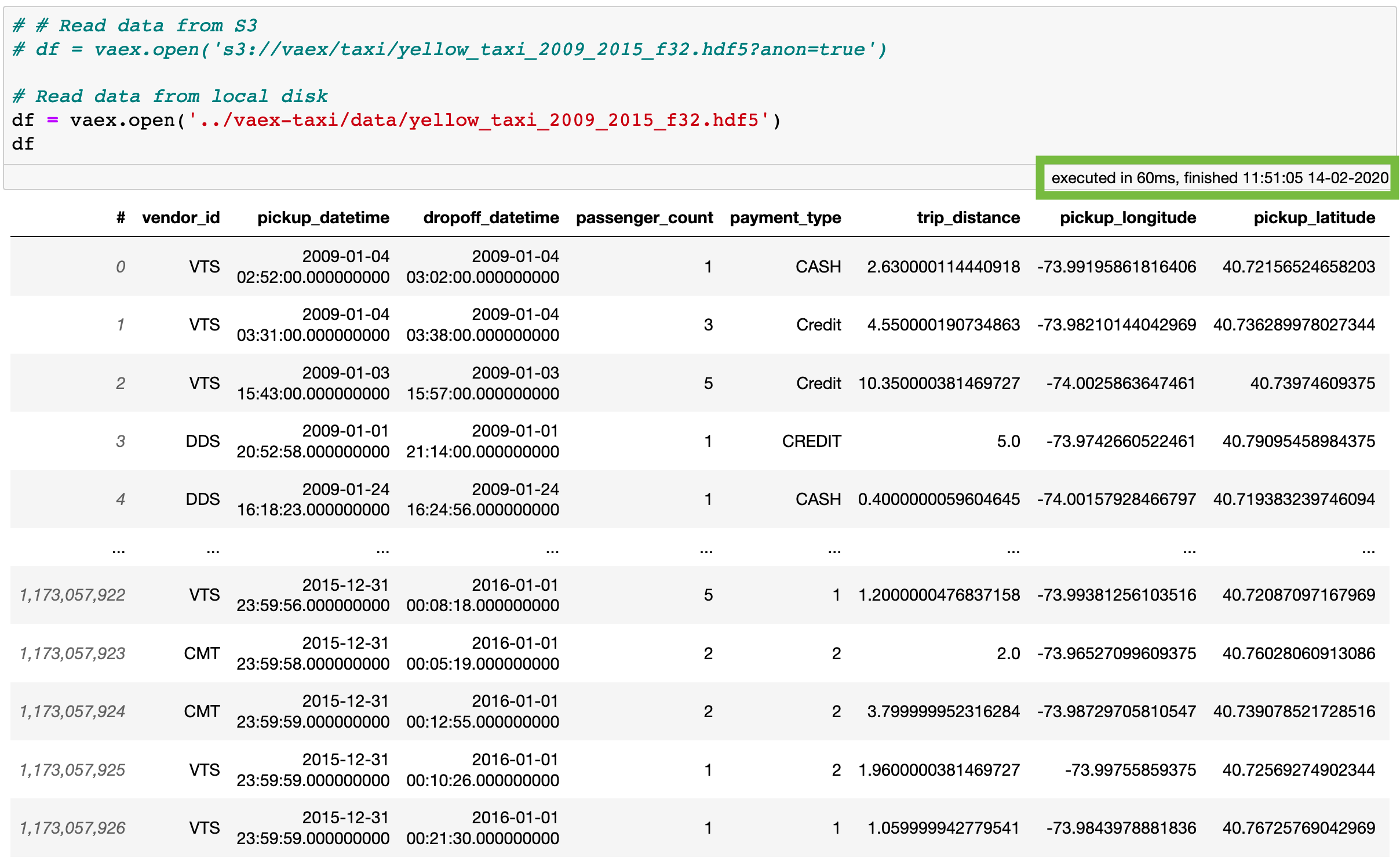 Opening and previewing a 100GB file with Vaex is instant.
Opening and previewing a 100GB file with Vaex is instant.
2. No memory copies
Vaex has a zero memory copy policy. This means that filtering a DataFrame costs very little memory and does not copy the data. Consider the following example.
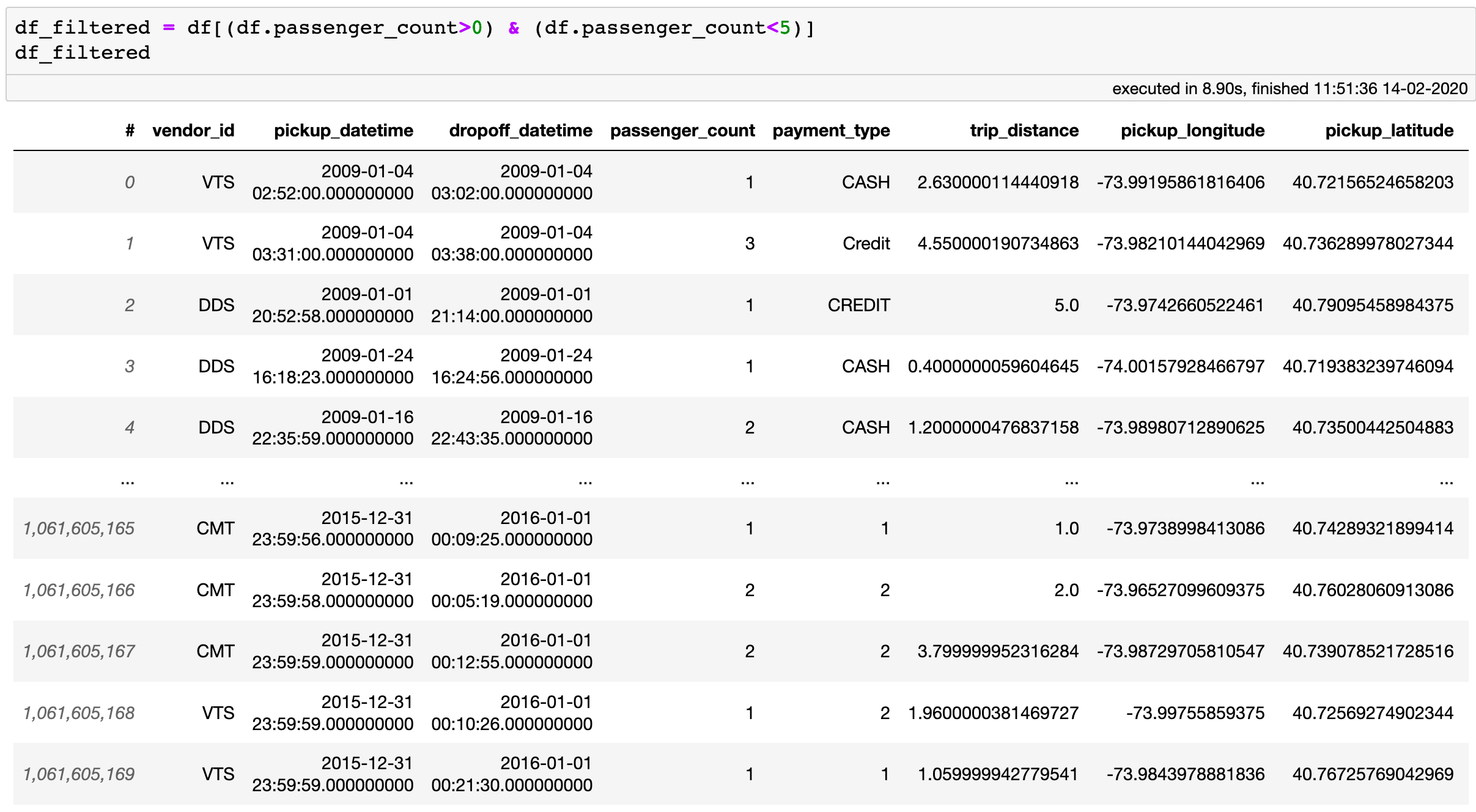 Filtering a Vaex DataFrame does not copy the data and takes negligible amount of memory.
Filtering a Vaex DataFrame does not copy the data and takes negligible amount of memory.
The creation of the df_filtered DataFrame takes no extra memory! This is because df_filtered is a shallow copy of df. When creating filtered DataFrames, Vaex creates a binary mask which is then applied to the original data, without the need to make copies. The memory costs for these kind of filters are low: one needs ~1.2 GB of RAM to filter a 1 billion row DataFrame. This is negligible compared to other "classical" tools where one would need 100GB to simply read in the data, and another ~100GB for the filtered DataFrame.
3. Virtual columns
Transforming existing columns of a Vaex DataFrame into new ones results in the creation of virtual columns. Virtual columns behave just like normal ones, but they take up no memory what so ever. This is because Vaex only remembers the expression the defines them, and does not calculate the values up front. These columns are lazily evaluated only when necessary, keeping memory usage low.
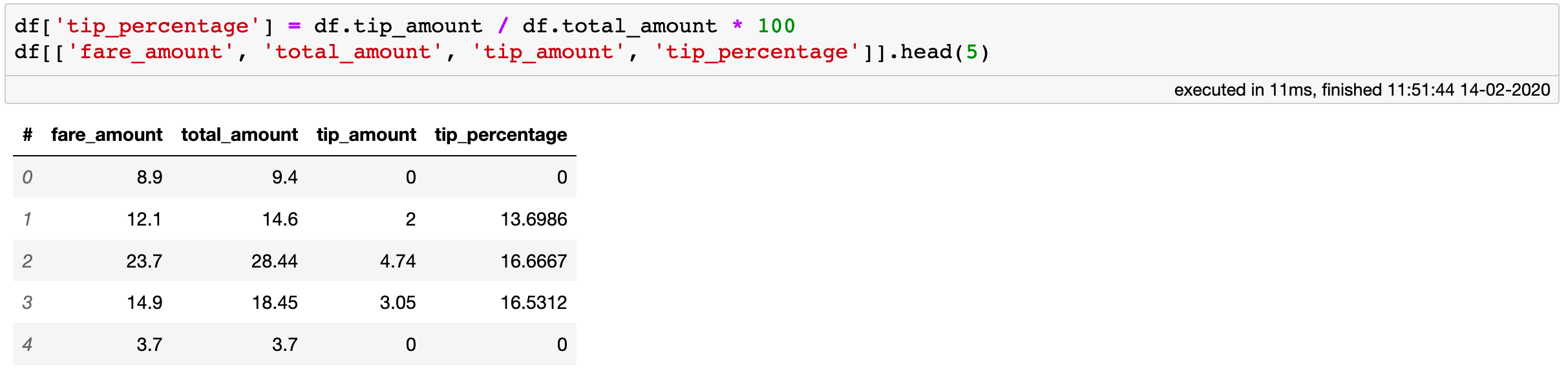 The “tip_percentage” column is a virtual column: it take no extra memory and is lazily evaluated on the fly when needed.
The “tip_percentage” column is a virtual column: it take no extra memory and is lazily evaluated on the fly when needed.
4. Performance
Vaex is fast. I mean seriously fast. The evaluation of virtual columns is fully parallelized and done with one pass over the data. Column methods such as “value_counts”, “groupby” , “unique” and the various string operations all use fast and efficient algorithms, implemented in C++ under the hood. All of them work in an out-of-core fashion, meaning you can process much more data than you fit into RAM, and use all available cores of your processor. For example, doing a “value_counts” operation takes only a second for over 1 billion rows!
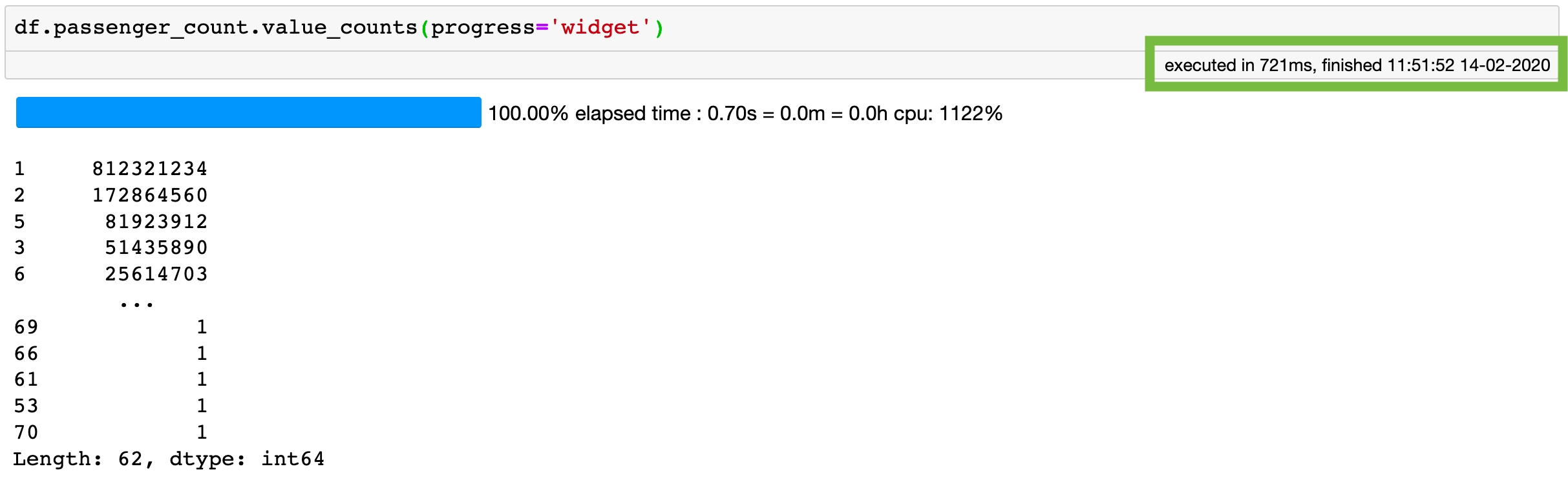 Using Vaex, the “value_counts” operation takes ~1s for over 1.1 billion rows!
Using Vaex, the “value_counts” operation takes ~1s for over 1.1 billion rows!
5. Just-In-Time Compilation
As long as a virtual column is defined only using Numpy or pure Python operations, Vaex can accelerate its evaluation by jitting, or Just-In-Time compilation via Numba or Pythran. Vaex also supports acceleration via CUDA if your machine has a CUDA enabled NVIDIA graphics card. This can be quite useful for speeding up the evaluation of rather computationally expensive virtual columns.
Consider the example below. I have defined the arc distance between two geographical locations, a calculation that involves quite some algebra and trigonometry. Calculating the mean value will force the execution of this rather computationally expensive virtual column. When the execution is done purely with Numpy, it takes only 30 seconds, which I find impressive given that it is done for over 1.1 billion rows. Now, when we do the same with the numba pre-compiled expression, we get ~2.5 times faster execution time, at least on my laptop. Unfortunately, I do not have an NVIDIA graphics card so I can not do the same using CUDA at this time. If you do, I’ll be very happy if you could try this out and share the results.
A small but important bonus: Notice the lack of a .compute or any such method — Vaex automatically knows when to be lazy and when to execute a computation.
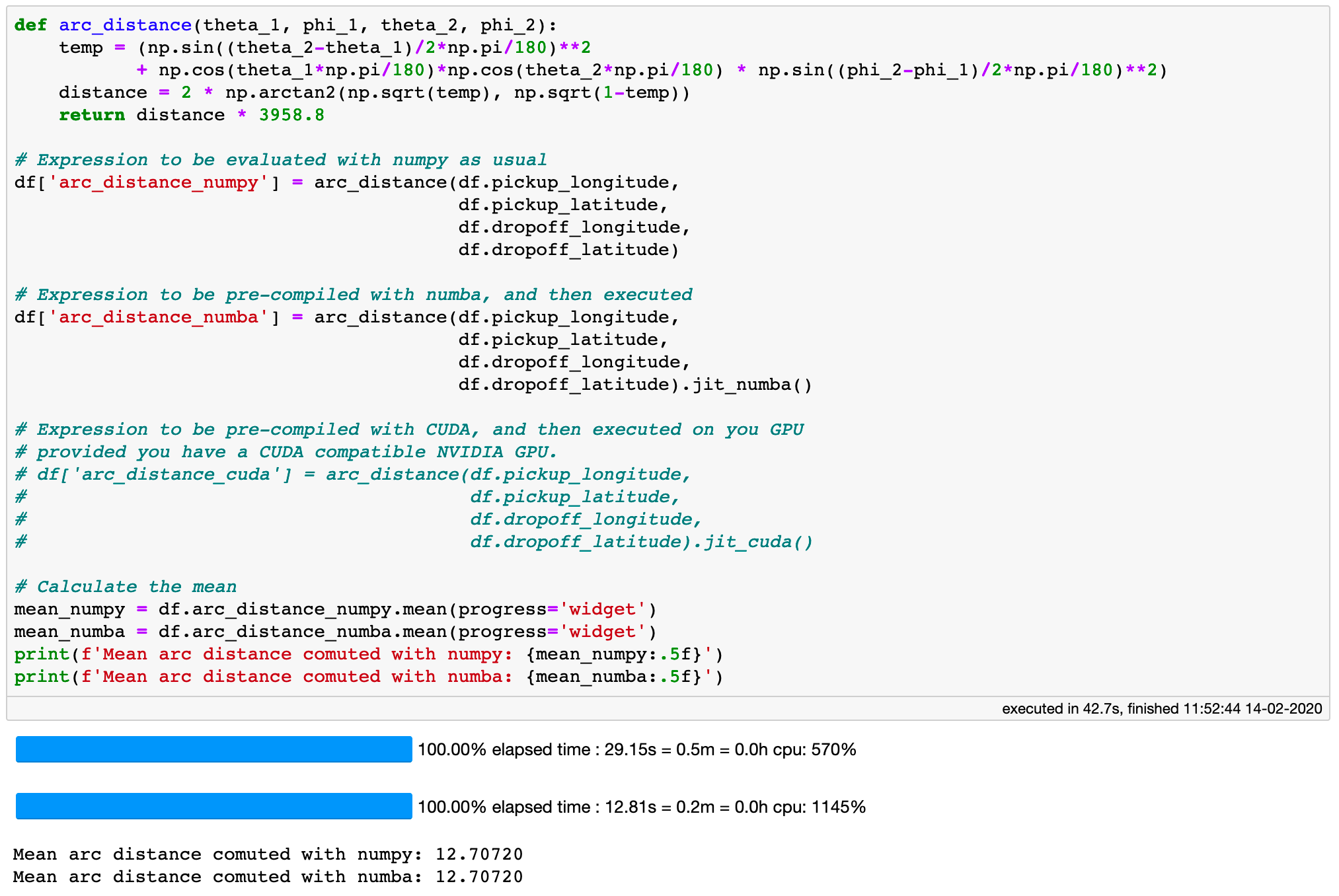 Jitting can lead to ~2.5 time faster execution times for a computationally expensive virtual column.
Jitting can lead to ~2.5 time faster execution times for a computationally expensive virtual column.
6. Selections
Vaex implements a concept called selections which is used to, ah, select the data. This is useful when you want to explore the data by, for example, calculating statistics on different portions of it without making a new reference DataFrame each time. The true power of using selections is that we can calculate a statistic for multiple selections with just one pass over the data.
 You can calculate statistics for multiple selections with one pass over the data.
You can calculate statistics for multiple selections with one pass over the data.
This can be also useful for making various visualisations. For example, we can use the .count method to create a couple of histograms on different selections with just one pass over the data. Quite efficient!
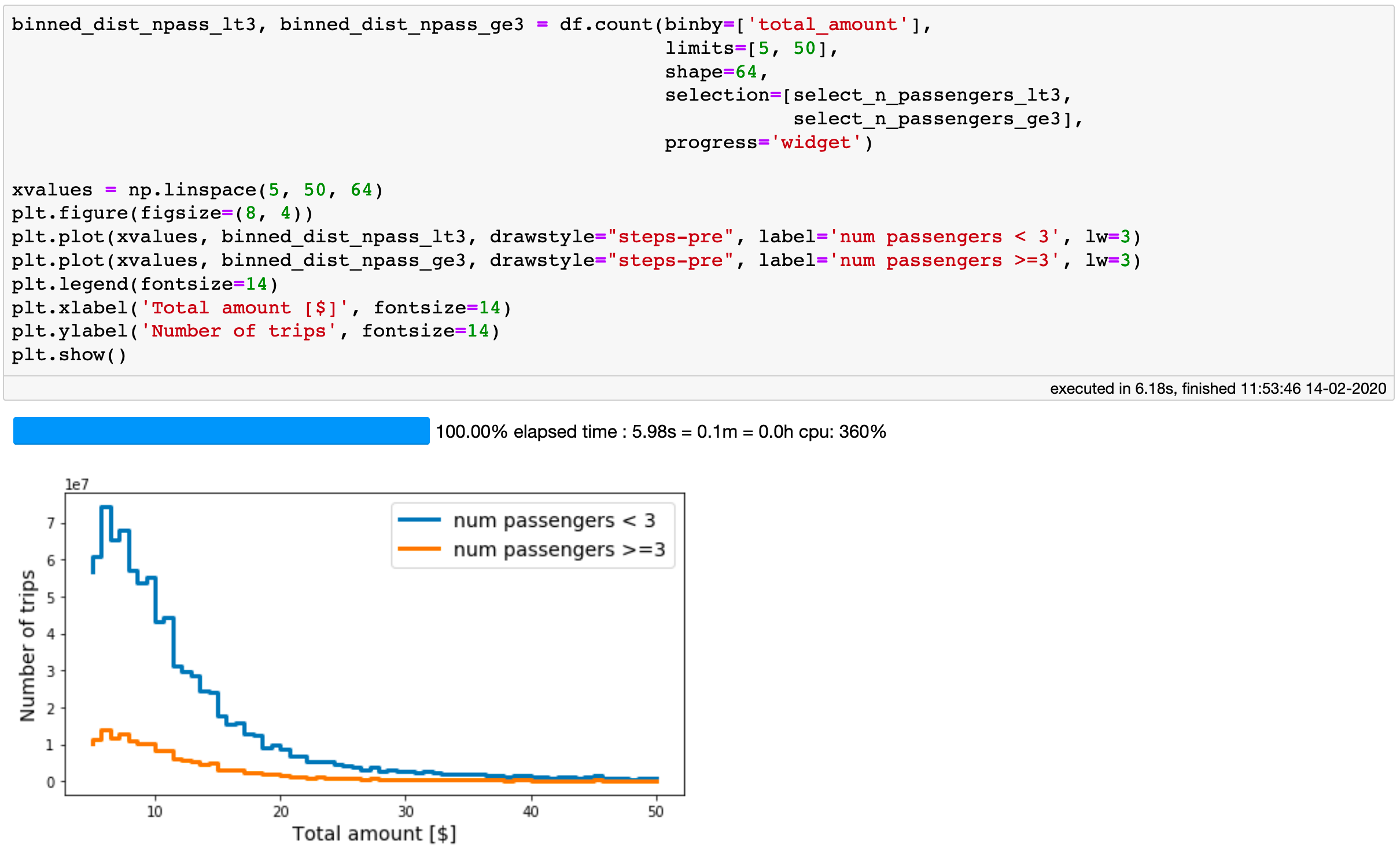 One can create multiple histograms on different selections with just one pass over the data.
One can create multiple histograms on different selections with just one pass over the data.
7. Groupby aggregations with selections
One of my favourite features of Vaex is the ability to use selections inside aggregation functions. I often find myself wanting to do a group-by operation, in which the aggregations follow some additional rule or filter. The SQL-esque way of doing this would be to run several separate queries in which one would first filter the data, then do the group-by aggregation, and later join the outputs of those aggregations into one table. With Vaex, one can do this with a single operation, and with just one pass over the data! The following group-by example, ran on over 1.1 billion rows takes only 30 seconds to execute on my laptop.
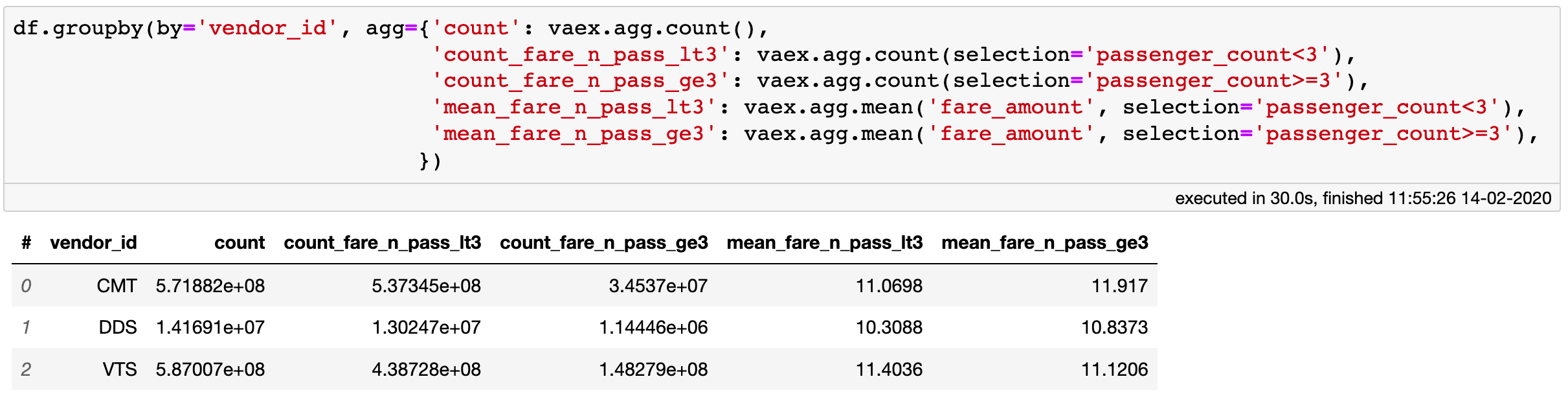 Selections can be used inside groupby aggregation functions.
Selections can be used inside groupby aggregation functions.
Bonus: Progress bars
Looking at the examples above, you may have noticed many of the methods implemented in Vaex are accompanied by a progress bar. I absolutely love this feature! Since I often use Vaex with larger datasets, knowing how long an operation is likely to take is very handy. Besides, it looks pretty and it makes time go by faster :).
Vaex is a rather powerful DataFrame library, especially when it comes to larger datasets. It has a variety of useful methods for data manipulation and visualization. These are just my top 7 reasons why I like working with this library. What are yours?